The Beginner’s Guide to Robots Meta Tags for SEO

Understanding robots meta tags can seem technical, but it’s vital knowledge for managing how search engines interact with your website. This guide will simplify robots meta tags, helping you learn how they work, how to control your page’s visibility, and how to make the most of these directives for better SEO performance.
What Are Robots Meta Tags?
Robots meta tags are pieces of HTML code that provide instructions to search engine crawlers. These instructions include whether a page should appear in search results, whether links on the page should be followed, and if the page content should be cached by the search engine.
How Does the Robots Meta Tag Work?
A robots meta tag sits in the HTML code within the <head> section of a webpage. Each robots tag contains two main components:
1. The name: The term “robots” tells search engines that these are instructions for the crawlers.
2. The content value: This includes directives (instructions), such as “index” or “noindex,” telling crawlers what actions to take.
When a crawler, like Googlebot, scans the page, it reads the robots tag and follows the given instructions. Based on your setup, it might index the page, ignore it, follow the links on it, or cache the content for future reference.
Key Robots Meta Tag Directives
Let’s break down some of the most common directives you’ll encounter:
1. Index / No-index:
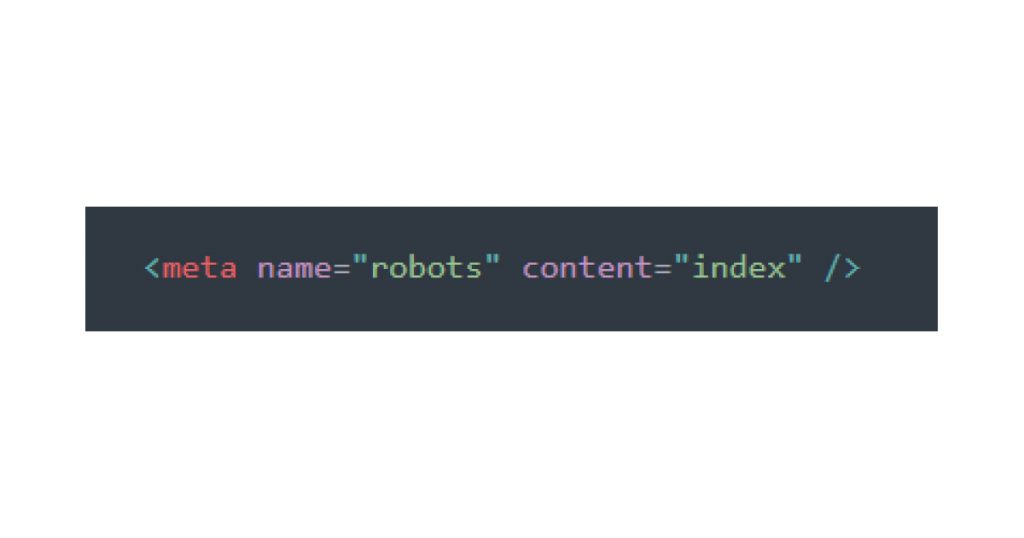
a). index: Allows the page to appear in search engine results. This is the default if no tag is specified.
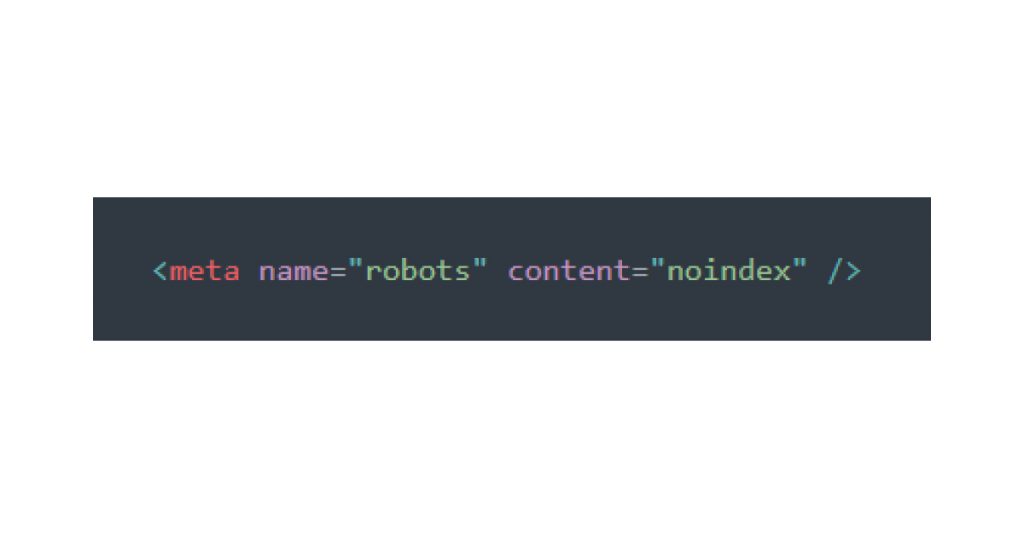
b). noindex: Prevents the page from appearing in search results. Use this for pages that shouldn’t show up in a search, like test pages or internal resources.
2. Follow / No-follow:
a). follow: Lets the search engine follow links on the page and pass any link value (PageRank) through them.

b). nofollow: Prevents the crawler from following links on the page, meaning it won’t pass any link value.

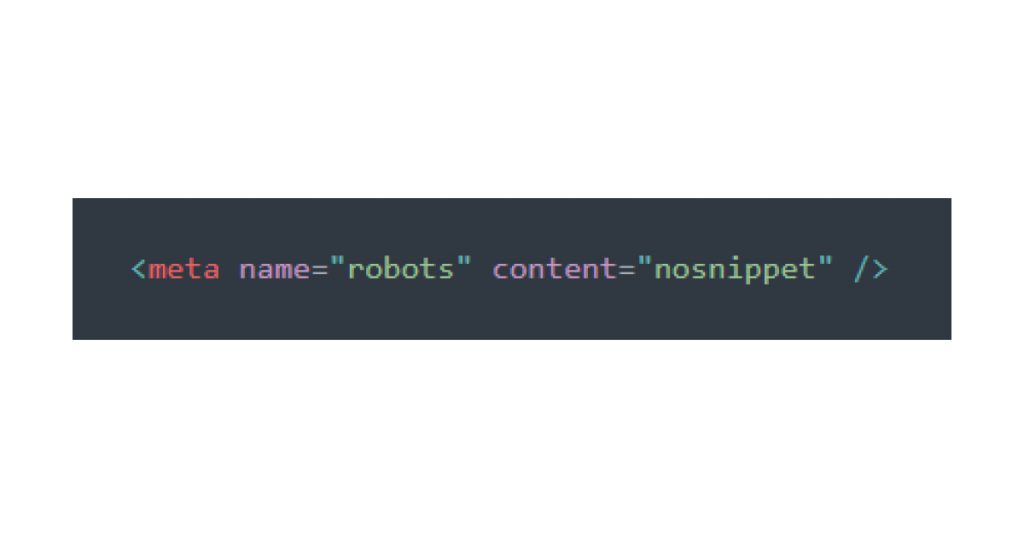
3. Nosnippet:
Stops search engines from displaying a text snippet or video preview in search results. Useful if you don’t want certain text from your page showing up.
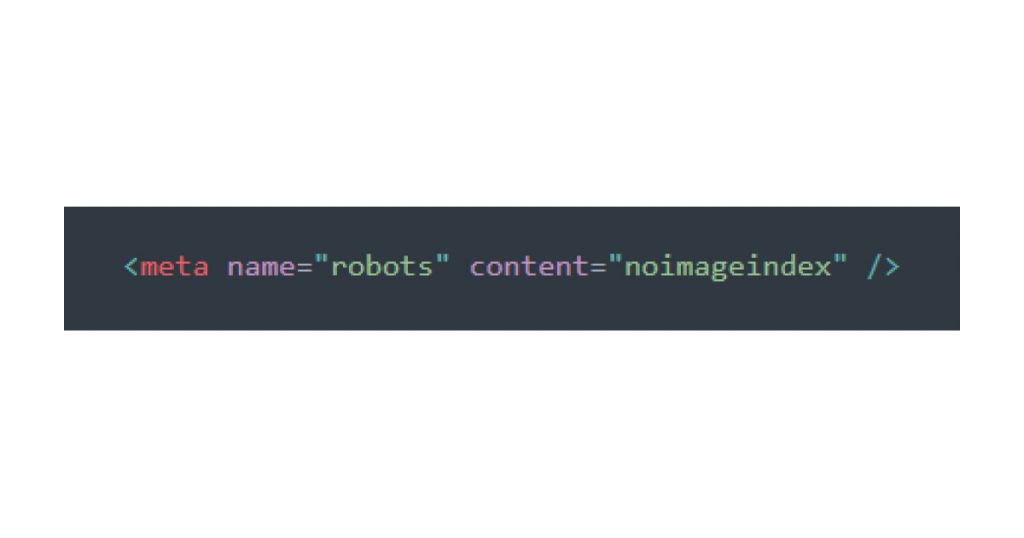
4. Noimageindex:
Specifically for images, this prevents the search engine from indexing images on the page. It’s handy if you want to protect image content from appearing in Google Images.
Each of these tags gives you control over different aspects of search engine visibility. Mixing and matching them is possible; for example, you might use noindex, follow if you want to hide a page from search results but still have crawlers follow its links.
Indexation-Controlling Parameters
Indexation control is about choosing which pages appear in search results and which ones don’t. A well-managed robots meta tag strategy can help you ensure only your most relevant content is indexed and shown to users, while less relevant or duplicate content remains out of sight.
Why Does This Matter?
A site with too many low-value pages indexed can suffer from “index bloat,” which can dilute the overall quality signals your site sends to search engines. Good use of robots tags helps prevent this, ensuring that your primary pages get the attention they deserve.
Types of Robots Meta Directives and Their Uses
Robots meta tags come in a variety of forms, and understanding their purposes can help you make better decisions about which tags to apply to different pages. Here’s a quick guide to each type:
1. Standard Robots Meta Tag:
This includes general commands such as index, noindex, follow, and nofollow to instruct search engines on what to do with the page and its links.

2. Google-Specific Tags:
Some tags, like nosnippet and noimageindex, are unique to Google. They control things like whether snippets show up in search or if images are included. These can be valuable if you’re focused on tailoring how Google represents your content.
3. X-Robots-Tag:
The X-Robots-Tag is a bit different from standard meta tags. Instead of being placed in a page’s HTML, it’s added to the HTTP header. This is useful when you need to apply directives to non-HTML files, such as PDFs or images.
4. Page-Specific Expiry with unavailable_after:
If you have a page with time-sensitive information, unavailable_after is your go-to directive. By setting a specific date and time, you ensure that a page no longer appears in search results after a certain date, perfect for limited-time offers or events.
Wrapping Up
Robots meta tags are a straightforward but powerful tool for SEO control. Knowing when and how to use directives like index, noindex, nofollow, and noarchive can keep your website’s visibility sharp, its search results clean, and its user experience focused. Remember that these tags are about managing attention—guiding search engines to prioritize the content that matters most.



